开始
了解
互联网正逐渐成为人们生活中的一部分,也越来越能够反映人们的想法、生活状态,而社交网络尤其具有代表性。在现代社会,查看社交网络主页甚至成为了人们了解一个人首要选择的途径。对社交网络的海量信息进行数据挖掘与分析也是当下一个必然的趋势。
1. 通过网络爬虫,获取人人网新鲜事/状态关键字搜索结果,将海量信息存入数据库
2. 通过对状态关键字搜索结果的数据分析,得到各关键词提到频率的学校排名
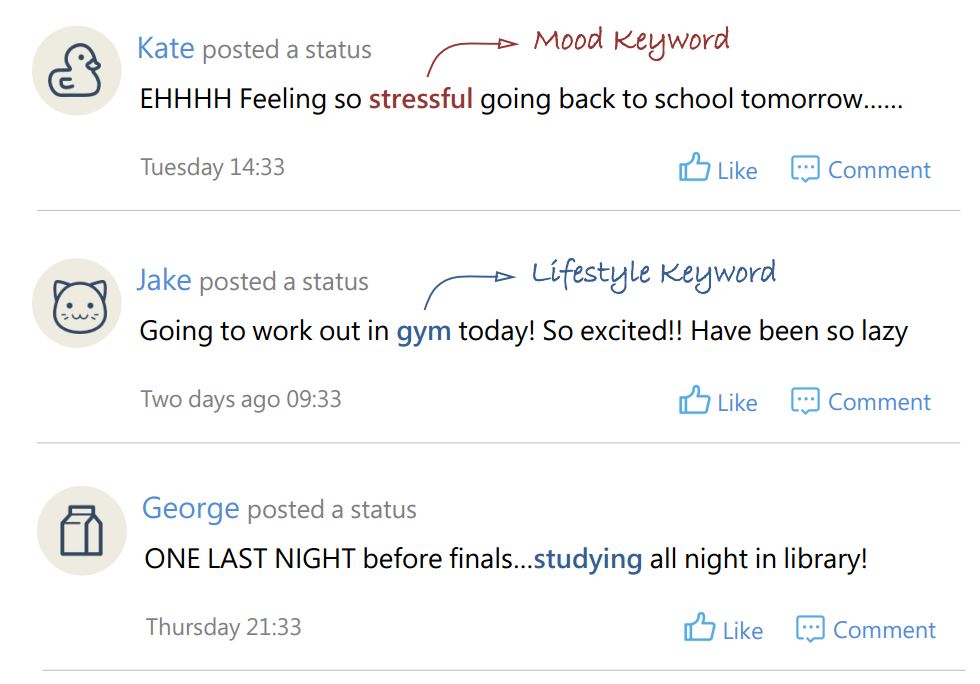
3. 通过对社交网络中学生发布的新鲜事或微博的词频统计,深入挖掘中国各高校学生生活状态,如学业压力、娱乐生活等
4. 通过社交网络用户档案分析,得到各高校学生的基本构成,比如男女比例,各地域比例,毕业去向分析,比如进入各研究所或工作单位比例
Renren (人人) 是目前规模最大的校园社交网络 它是学生主要的校园信息发布与获取的渠道。在移动互联的时代,每个人不仅是浏览者更是互联网内容的贡献者,每天上亿的信息与内容在互联网上传播与发布。